Creating a Custom LLM Evaluator with a Benchmark Dataset
Learn how to build a custom LLM-as-a-Judge evaluator by creating a benchmark dataset tailored to your use case, enabling rigorous evaluation beyond standard templates.
Google Colab
colab.research.google.com
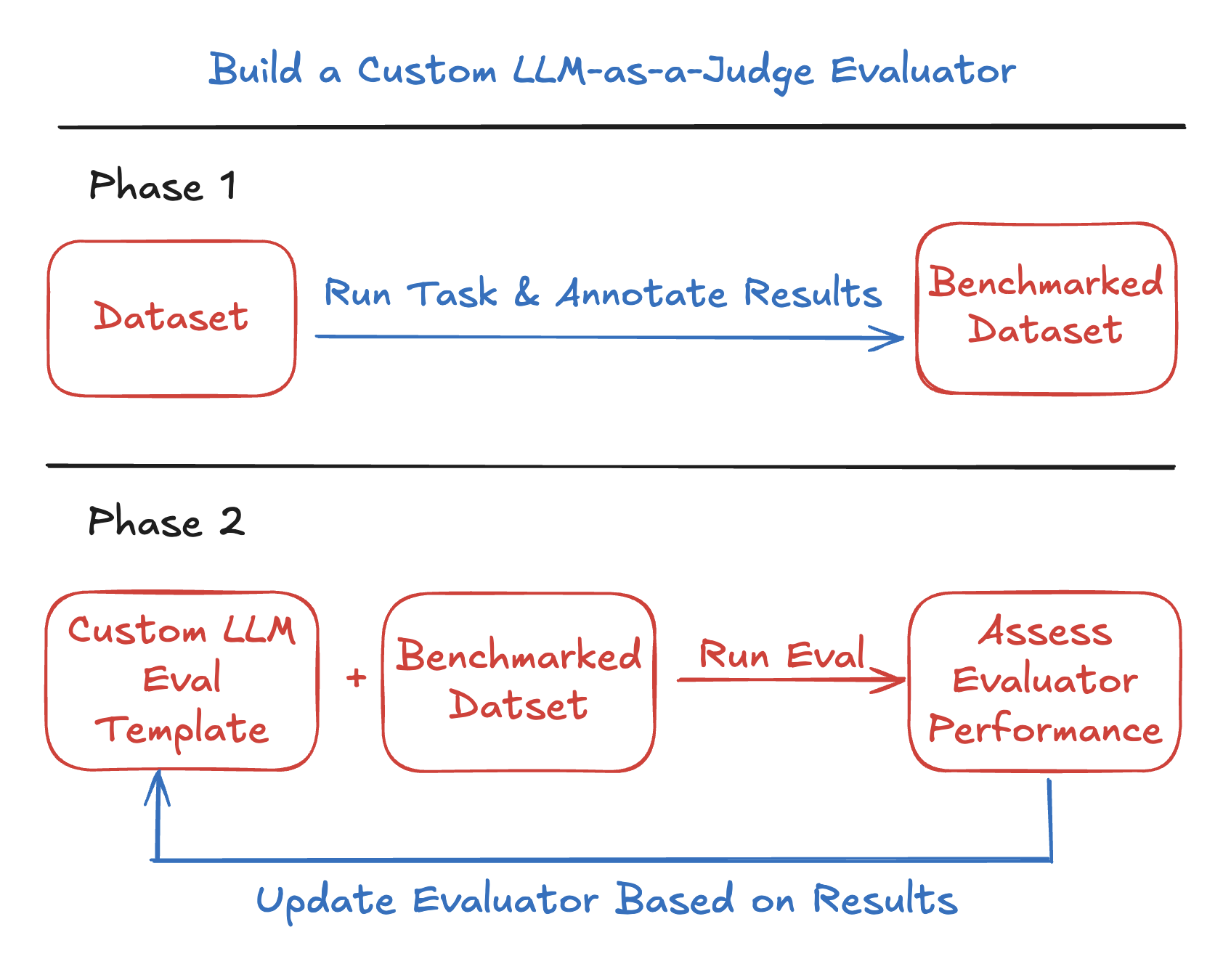
A good evaluator measures what you actually care about — and the only way to know it does is to test it against examples you’ve judged yourself. Phoenix ships several pre-built evaluators that have been validated against benchmark datasets, but these may not capture the nuances of your application.So how do you achieve that same rigor when your use case falls outside the scope of standard evaluators? You build the evaluator the same way the pre-built ones were built. This tutorial walks through the three steps:
Build a benchmark dataset — a small set of human-annotated examples that capture your definition of “good.”
Write the judge prompt — the LLM-as-a-Judge template that encodes that definition.
Validate before you trust it — measure how well the judge agrees with your human labels, and iterate until it does.
Prefer to watch? The full walkthrough is below; otherwise, follow the key snippets on this page.
The diagram below provides an overview of the process we will follow in this walkthrough.
We will go through key code snippets on this page. To run the full tutorial end-to-end, open the Colab notebook above, or check out the video for a guided walkthrough.
In this tutorial, we’ll ask an LLM to generate expense reports from receipt images provided as public URLs. Running the cells below will generate traces, which you can explore directly in Phoenix for annotation. We’ll use GPT-5.5, which supports image inputs.
The sample images below are public receipt photos from the Wikimedia Commons Receipts category (Creative Commons licensed). Swap in your own receipt URLs to build traces for your use case.
First, connect to Phoenix and auto-instrument OpenAI so every call is traced to a project. We name the project receipt-classification — the same identifier we’ll query when building the benchmark dataset below.
# pip install arize-phoenix-client arize-phoenix-evals arize-phoenix-otel openinference-instrumentation-openai openai pandasimport osfrom getpass import getpassfrom phoenix.otel import register# Prompt for any keys not already set in the environment (don't clobber real values).if not os.environ.get("PHOENIX_API_KEY"): os.environ["PHOENIX_API_KEY"] = getpass("Enter your Phoenix API key: ")if not os.environ.get("OPENAI_API_KEY"): os.environ["OPENAI_API_KEY"] = getpass("Enter your OpenAI API key: ")# For Phoenix Cloud, also point at your space's collector endpoint, e.g.:# os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com/s/your-space"tracer_provider = register( project_name="receipt-classification", auto_instrument=True, # instruments installed libraries, including OpenAI)
from openai import OpenAIclient = OpenAI()def extract_receipt_data(input): response = client.chat.completions.create( model="gpt-5.5", messages=[ { "role": "user", "content": [ {"type": "text", "text": "Analyze this receipt and return a brief summary for an expense report. Only include category of expense, total cost, and summary of items"}, { "type": "image_url", "image_url": { "url": input, }, }, ], } ], max_tokens=500, ) return response
By following the auto-instrumentation setup, running the code below will automatically send traces to Phoenix.
# Public receipt images (Wikimedia Commons). Swap in your own to build traces.urls = [ "https://upload.wikimedia.org/wikipedia/commons/2/25/Receipt.jpg", "https://upload.wikimedia.org/wikipedia/commons/d/df/Save_Mart_recipt_2010-10-23.jpg", "https://upload.wikimedia.org/wikipedia/commons/9/9e/Restaurant_Bill_1_2013-07-08.jpg",]for url in urls: extract_receipt_data(url)
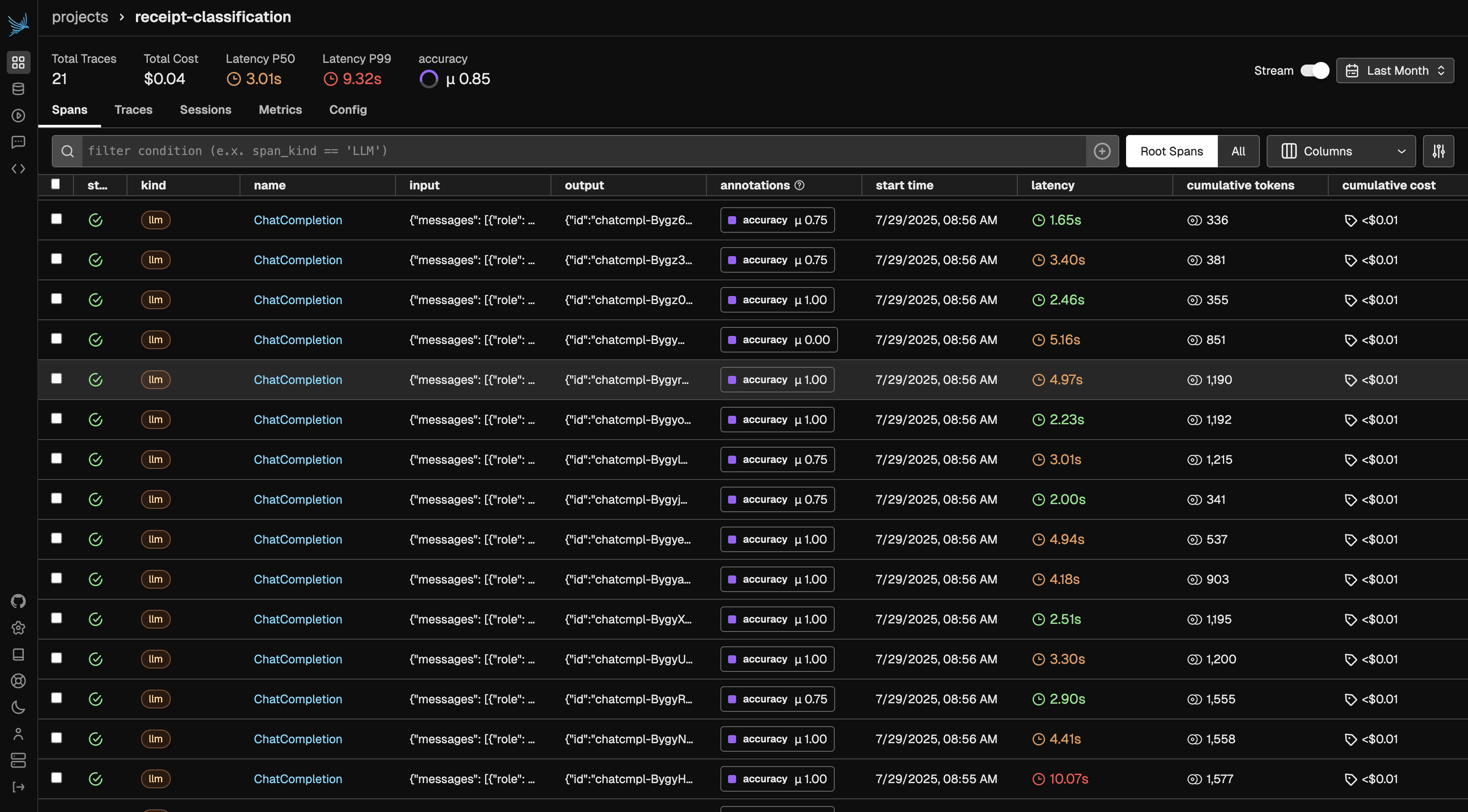
After generating traces, open Phoenix to begin annotating your dataset. In this example, we’ll annotate based on “accuracy”, but you can choose any evaluation criterion that fits your use case. Just be sure to update the query below to match the annotation key you’re using—this ensures the annotated examples are included in your benchmark dataset.
import osimport pandas as pdfrom phoenix.client import Clientfrom phoenix.client.types import spansclient = Client(api_key=os.getenv("PHOENIX_API_KEY"))# replace "accuracy" if you chose to annotate on different criteriaquery = spans.SpanQuery().where("annotations['accuracy']")spans_df = client.spans.get_spans_dataframe(query=query, project_identifier="receipt-classification")annotations_df = client.spans.get_span_annotations_dataframe(spans_dataframe = spans_df, project_identifier="receipt-classification")full_df = annotations_df.join(spans_df, how = "inner")# create_dataset serializes the DataFrame as CSV, so a nested column like# attributes.llm.output_messages is stored as a string and can't be indexed later.# Flatten the model's response to plain text up front so the evaluator can read it.def first_message_content(messages): # get_spans_dataframe returns output_messages as a list of message dicts; # guard against empty rows (and the occasional already-stringified value). if isinstance(messages, list) and messages: return messages[0].get("message.content", "") if isinstance(messages, str): return messages return ""full_df["output_text"] = full_df["attributes.llm.output_messages"].apply(first_message_content)from phoenix.client import Clientdataset = Client().datasets.create_dataset( name="annotated-receipts", dataframe=full_df, input_keys=["attributes.input.value"], output_keys=["output_text"], metadata_keys=["result.label", "result.score", "result.explanation"],)
Next, we’ll create a baseline evaluation template and define both the task and the evaluation function. Once these are set up, we’ll run an experiment to compare the evaluator’s performance against our ground truth annotations. In this case, our task function calls evaluator.evaluate() directly with a ClassificationEvaluator and our evaluator is a comparison between the task output and our annotated labels.
Phoenix evals does not yet support multimodal inputs (e.g. images). The evaluator below assesses the expense report text output for completeness and structure rather than comparing against the original receipt image.
choices = ["accurate", "almost accurate", "inaccurate"]prompt_template = """You are an evaluator tasked with assessing the quality of a model-generated expense report.The model was instructed to analyze a receipt image and return a brief summary including: category of expense, total cost, and summary of items.---MODEL OUTPUT (Expense Report): {output}---Evaluate whether the expense report is complete and well-structured. Assign one of the following labels. Only include the label:- **"accurate"** – Includes expense category, total cost, and item summary; all information looks reasonable- **"almost accurate"** – Mostly correct but with small issues (e.g., missing one element or vague category)- **"inaccurate"** – Substantially wrong or missing critical information"""
Next, we’ll refine our evaluation prompt template by adding more specific instructions to classification rules. We can add these rules based on gaps we saw in the previous iteration. This additional guidance helps improve accuracy and ensures the evaluator’s judgments better align with human expectations.
prompt_template = """You are an evaluator tasked with assessing the quality of a model-generated expense report.The model was instructed to analyze a receipt image and return a brief summary including: category of expense, total cost, and summary of items.---MODEL OUTPUT (Expense Report): {output}---Evaluate the following and assign one of the following labels. Only include the label:- **"accurate"** – Total price, itemized list, and expense category are all present and look reasonable. All three must be present to get this label.- **"almost accurate"** – Mostly correct but with small issues. For example, expense category is too vague or one element is missing.- **"inaccurate"** – Substantially wrong or missing critical information. For example, missing total price entirely."""receipt_evaluator = ClassificationEvaluator( name="receipt_accuracy", prompt_template=prompt_template, llm=llm, choices=choices,)
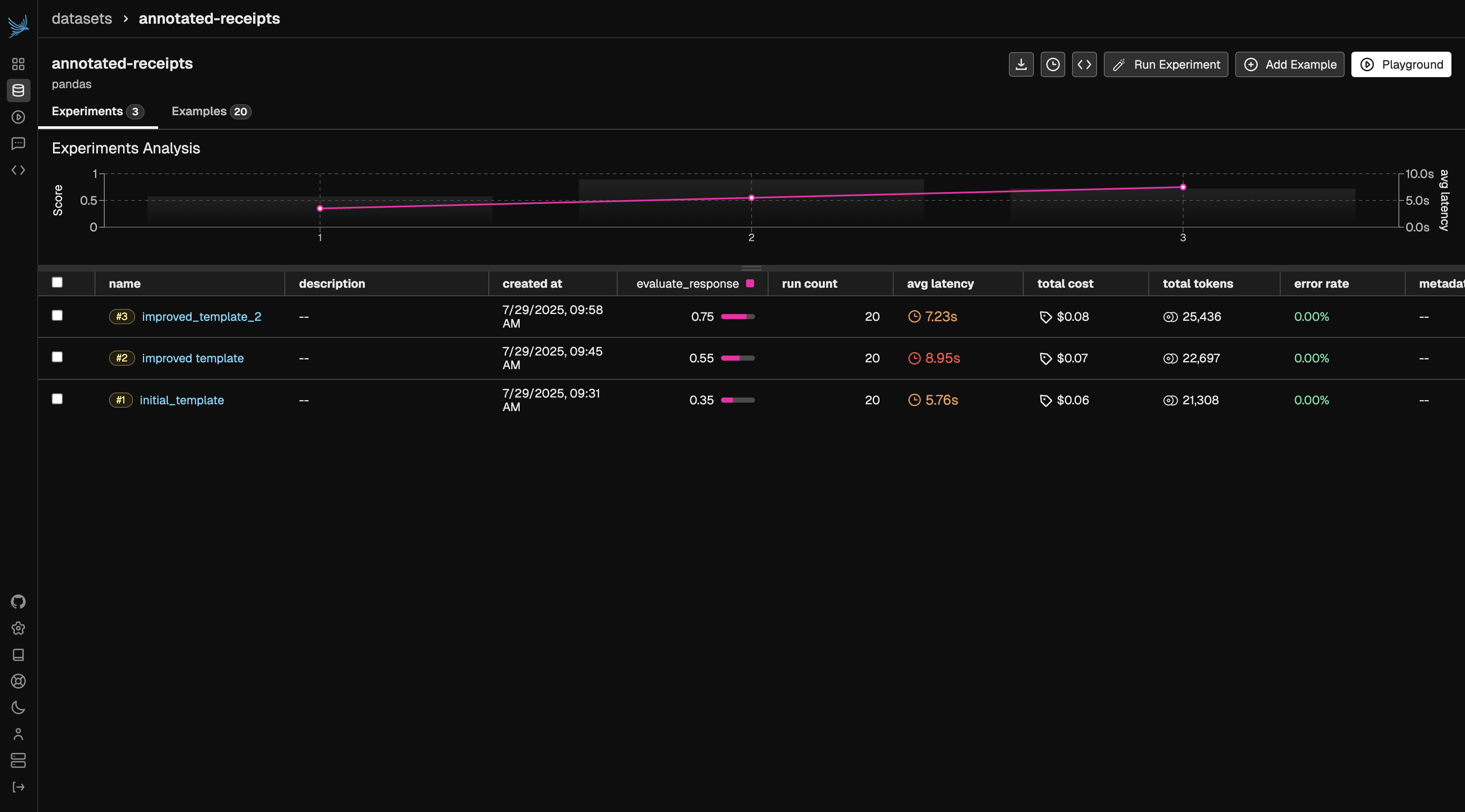
Each experiment run reports how often the judge’s label matched your human annotation — that agreement score is your validation signal. It’s the number that tells you whether the evaluator measures what you actually care about, and it’s exactly the kind of benchmarking the pre-built evaluators go through before they ship.Compare the two runs in Phoenix:
The initial template establishes your baseline agreement with the human-labeled benchmark.
The improved template should show measurably higher agreement, since its rules were written to close the specific gaps you saw in the first run.
There’s no universal pass mark — the target depends on your benchmark and how costly disagreements are for your use case. The key discipline is to not trust the judge in production until it aligns with your benchmark. A judge that agrees with you on the examples you’ve labeled is one you can extend to the traces you haven’t.When agreement falls short, inspect the disagreements: each mismatch is either a gap in the judge prompt (tighten the rules and re-run) or a sign your own labels aren’t consistent (refine the benchmark). Keep iterating until the evaluator meets the bar you’ve set.